
![]()
Intelligent audio listener
Objective
The goal of the project was to create a prototype that could locate and categorize sounds with a 360-degree microphone array. The gathered information about the environment should then be then presented to the user.
The purpose of our prototype is to quickly and easily get necessary data from the environment and transfer it to the user so that he can react to it and pass it on. Therefore enabling the user and his team to have a better picture of the environment they operate in.
To achieve the intended functionality, we decided to use 4 microphones mounted on the helmet of the user and a processing unit to handle data processing and necessary calculations. This enables us to use the powerful Raspberry Pi 4 to calculate the direction of sounds and use machine learning to classify them. To present the processed data to the user we decided to use a small display. Connected to the processing unit. Alternatively, text-to-speech could be used through a small speaker or headset.
Devices and components
Microphones
To get accurate and reliable data from the environment, we needed a suitable microphone. After trying a few mems-based options we landed on AGC Electret Microphones by Adafruit. The microphone circuit has a built-in amplifier which made the development of our prototype faster, as no external amplifier was needed.
Analog to digital converter
To send the data to the processing unit, it first needs to be converted from an analog signal to a digital one. For this step, we used the MCP-3008 analog to digital converter, which communicates with the Raspberry Pi through SPI protocol. This converter enabled us to reach a sampling rate of 10 kHz per channel. Later on in the project, we decided to test out the ADS8688, a faster analog to digital converter with a higher resolution of 16 bits instead of the 10-bits of the MCP-3008. However, we did not have time to implement this converter in the final prototype.
Raspberry Pi
For data processing and algorithms we used the Raspberry Pi 4 by Raspberry Pi Foundation. This was a good option for us, as it provides enough processing power to run machine learning algorithms for sound classification.
Display
To present the gathered information to the user we decided to use the SSD1306 LCD by Adafruit. The display communicates with the Raspberry Pi Through I²C.
Design and hardware.
Modeling
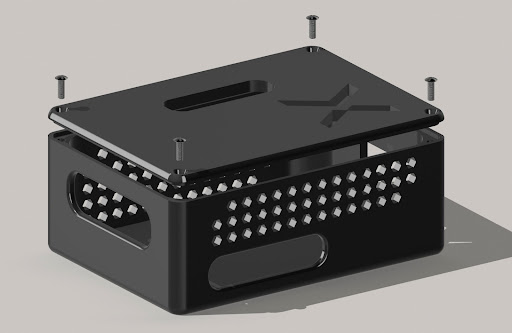
For attaching the microphones to the helmet, we designed an attachment mechanism. For the Raspberry pi and analog to digital converter, we designed suitable housings. Modeling was done in Solidworks and Shapr3d.

Circuit design
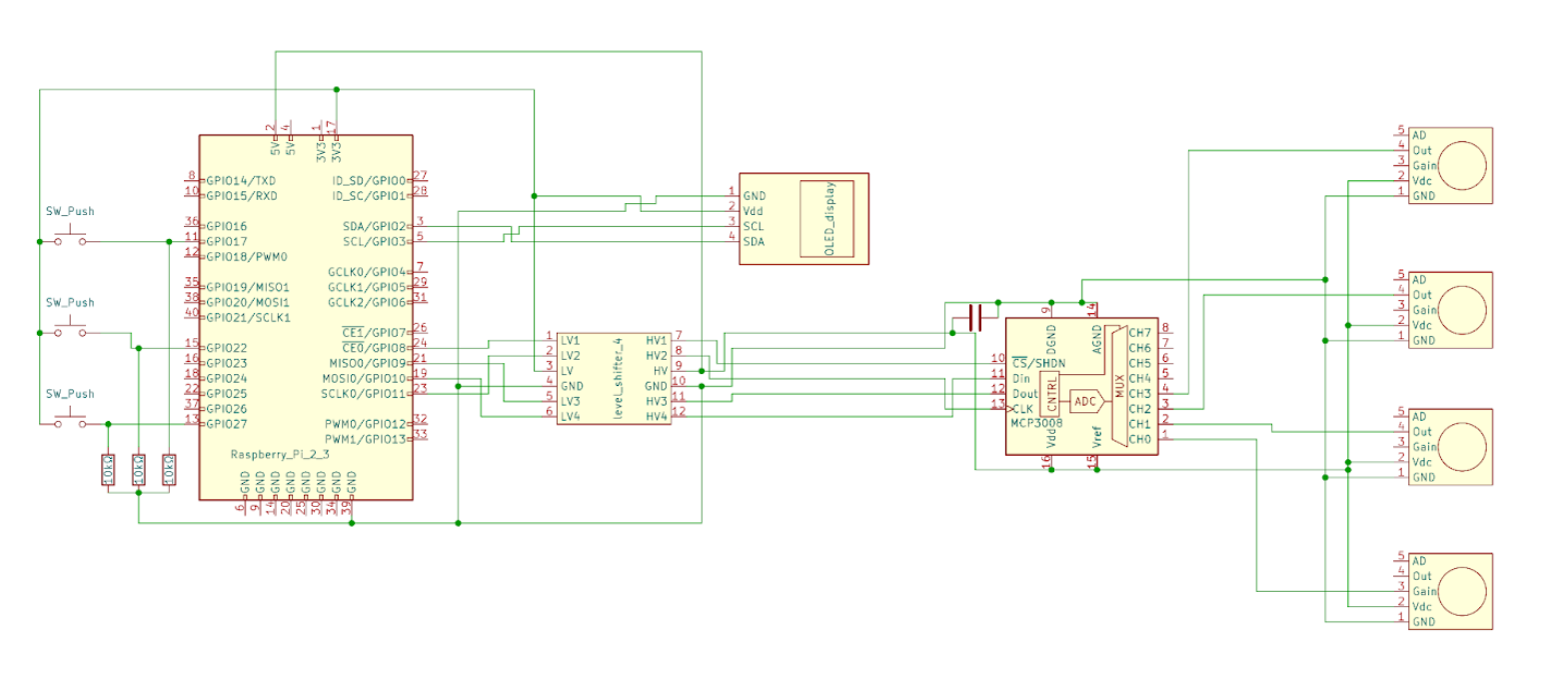
For the Raspberry pi, we designed a shield that helps with connecting the analog to digital converter and display. The shield also adds functionality with programmable buttons and contains a logic level shifter to step down the 5v signal coming from the converter to 3v, so that it can be read by the Raspberry Pi’s GPIO pins.
We also designed a circuit for the analog to digital converter. The circuit enables us to easily connect the 4 microphones to the inputs of the converter and the converter to the raspberry Pi. The converter circuit is located in a small box at the back of the helmet.
All circuits were designed in KiCad



Software
Embedded software was written in C and Python. C was used on the analog to digital converter for collecting data from the microphones due to its speed and low low overhead. For data analysis and machine learning on the Raspberry Pi, we used Python. The display driver is also written in Python.
Signal processing and ML
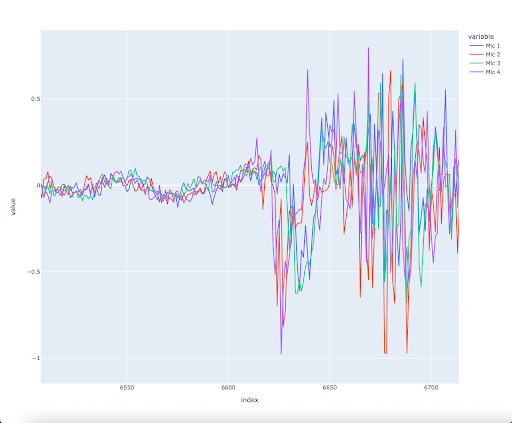
The raw data supplied by the analog to digital converter must is normalized before being used in calculations and machine learning.
Sound the direction of incoming sounds is calculated from the phase shift of sound. This is done by first detecting which two microphones the sound hits first and then calculating an angle from the phase difference of the signals. A constant is added based on which microphones are hit first. For example, if the two microphones at the back of the helmet are hit first, 180 degrees is added to get the real angle. With the current 10 kHz sample rate, it is possible to reach an accuracy of around 10 degrees. However, error measurements sometimes happen due to the relatively low sample rate. A higher sample rate would significantly increase accuracy and reliability.
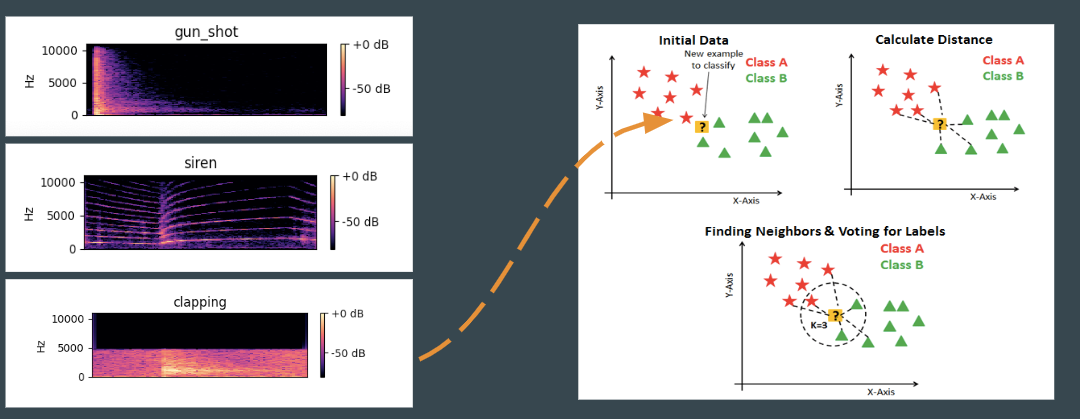
For sound classification, we used the K-nearest neighbor algorithm on a spectrogram of the recorded data. For training the model we used a free dataset the categories in this dataset are: Car horn, drilling, engine idling, gunshot, jackhammer, and siren. We also added clapping from recorded data as a new category to the dataset. With the training samples in the dataset, we achieved a 74% theoretical accuracy.
Result

Team
Pekka Parkkonen, Student of Electrical Engineering at Aalto University
Elmo Kankkunen, Student of Electrical Engineering at Aalto University
Markus Lång, Student of Electrical Engineering at Aalto University
Arun Bhatia, Student of Bioinformation technology at Aalto University
GitLab
https://version.aalto.fi/gitlab/protopaja-savox-2/intelligent-audio-listener